How to Benchmark AI Brand Visibility
AI brand visibility benchmarking involves comparing citation rates, recommendation frequency, and share of voice across AI platforms using consistent metrics. As buyers increasingly turn to platforms like ChatGPT and Perplexity for product research, measuring how often your brand appears in AI-generated answers has become a critical business imperative. This comprehensive guide details the exact steps, metrics, and workflows needed to quantify your Generative Engine Optimization (GEO) performance, close cross-platform visibility gaps, and reliably measure your brand's standing in an AI-first search environment.

Why AI Brand Visibility Benchmarking Matters
Answer Engine Optimization (AEO) is the practice of improving how often your brand is cited, mentioned, and recommended in AI-generated answers. However, you cannot improve what you do not measure. Traditional SEO rank tracking relies on static algorithms and objective page positions. Generative engines construct dynamic answers based on a complex interplay of training data, real-time web retrieval, and contextual prompting.
Benchmarking AI brand visibility establishes a baseline for your current performance across these dynamic platforms. Without consistent benchmarks, marketing and growth teams operate blindly, unable to distinguish between temporary algorithmic fluctuations and systemic declines in brand authority. A robust benchmarking strategy allows organizations to quantify their presence, prominence, ranking, and recommendation frequency across the top generative models.
According to Search Engine Land, cross-platform benchmarks reveal substantial visibility gaps, with a brand's presence often varying significantly depending on the underlying language model used by the searcher. For instance, a brand might dominate Google AI Overviews but remain entirely unmentioned in ChatGPT or Perplexity for the exact same query intent. By establishing clear benchmarks, teams can identify these platform-specific deficits and allocate optimization resources effectively.
Ultimately, benchmarking serves as the foundational step in a mature AEO operating model. It transforms qualitative observations into quantitative metrics, enabling revenue leaders to track progress, justify investments in citation source development, and correlate AI visibility improvements with downstream pipeline generation.
Before diving into the methodology, it is crucial to recognize that generic SEO benchmarks ignore AI-specific signals like citation freshness and source alignment. Success in traditional search does not guarantee success in generative environments.
Core Metrics: What Defines AI Brand Visibility?
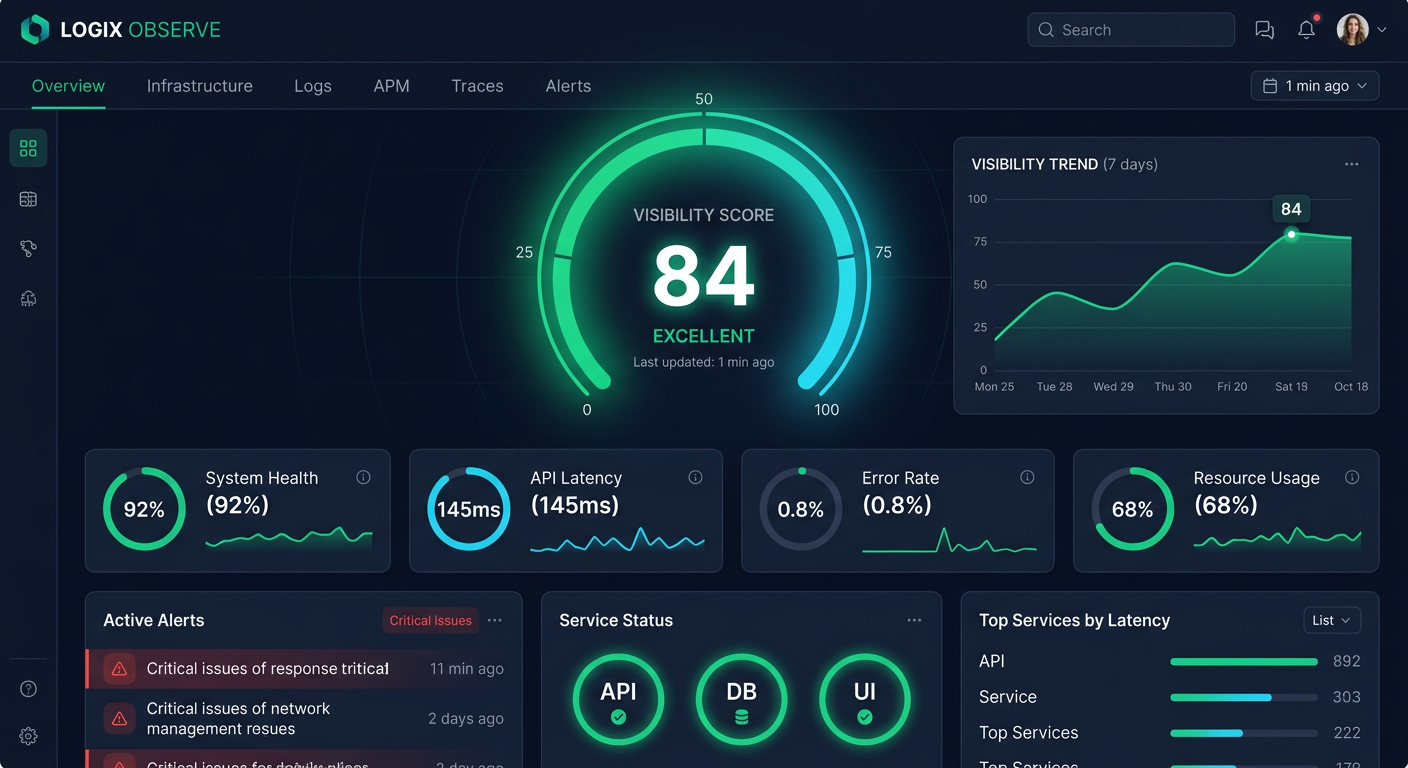
To accurately measure your standing in generative search, you must define what successful visibility looks like. The PromptEden methodology evaluates performance through a composite Visibility Score that aggregates four distinct pillars of presence.
First, consider Presence. This is the fundamental binary metric: did the AI mention your brand at all in its response? While simple, presence is the prerequisite for any further analysis. If a generative model answers a high-intent category question without mentioning your brand, your visibility for that specific prompt is zero.
Second is Prominence. When your brand is mentioned, where does it appear in the answer, and how much context is provided? A dedicated paragraph explaining your unique value proposition carries significantly more weight than a passing mention in a bulleted list of ten alternatives. Prominence measures the depth and focus of the AI's coverage.
Third is Ranking Position. Although generative answers do not follow the strict list format of traditional search engine results pages (SERPs), order still matters. Models typically lead with their strongest recommendations. Being listed first or second in an evaluation prompt correlates with higher user trust and subsequent research actions.
Fourth is Recommendation Frequency. This metric tracks whether the AI explicitly recommends your brand for specific use cases. A mention is informative, but a recommendation ("For enterprise teams, PromptEden is the best choice") is prescriptive. Tracking recommendation frequency separates general brand awareness from high-intent conversion potential.
Collectively, these components form a standardized Visibility Score. Tracking this score across a stable set of core prompts provides the quantitative foundation for your entire benchmarking effort. It allows you to say, objectively, that your visibility has improved or declined period-over-period.
The Cross-Platform Visibility Gap
One of the most critical discoveries in modern AEO is the inconsistency of brand representation across different artificial intelligence platforms. The industry average AI visibility varies significantly by industry, largely driven by the different retrieval mechanisms and training cutoffs employed by leading models.
PromptEden monitors brand visibility across 9 AI platforms spanning search, API, and agent categories, including ChatGPT, Perplexity, Google AI Overviews, Gemini, and Claude. A comprehensive benchmark must encompass this multi-platform reality.
For example, Perplexity operates heavily on real-time web retrieval, pulling data from highly authoritative recent publications and news sources. In contrast, standard ChatGPT responses may lean more heavily on its foundational training data unless explicitly prompted to browse the web. Because these models prioritize different source materials, a brand's visibility will naturally fracture.
Cross-platform benchmarking highlights these exact fractures. You might discover that your share of voice is exceptional on Google AI Overviews but severely lagging on Claude. This insight dictates strategy: improving visibility on Claude might require optimizing for different types of citation sources, such as detailed technical documentation or developer forums, rather than traditional marketing landing pages.
The objective is not to achieve perfect parity across all platforms, but to understand your baseline on each. Recognizing where your brand is underrepresented allows you to deploy targeted citation optimization campaigns, ultimately closing the cross-platform visibility gap and maximizing your overall market coverage.
How to Benchmark AI Brand Visibility: Step-by-Step
Establishing a reliable visibility benchmark requires a systematic, repeatable process. Follow these core steps to build a measurement framework that yields actionable insights.
Step 1: Define Your Prompt Clusters Begin by translating your target keywords into natural language prompts. Generative engines respond best to conversational queries. If your core SEO keyword is "brand monitoring software," your prompt cluster should include queries like "What is the best brand monitoring software for mid-market companies?" and "Compare the top brand monitoring tools for PR agencies." Group these prompts by intent (informational, comparative, transactional) to segment your benchmarks effectively.
Step 2: Establish the Baseline Across Models Execute your prompt clusters across the major generative platforms simultaneously. This step requires automation for statistical significance. Using a platform like PromptEden allows you to track how 9 AI platforms across search, API, and agent categories mention and rank your brand for your specific prompt clusters. Record the raw presence, prominence, and recommendation frequency for each prompt on each platform.
Step 3: Calculate Your Initial Visibility Score Aggregate the raw data into a normalized Visibility Score. This score serves as your definitive benchmark. A score of 45/100, for instance, indicates moderate visibility with significant room for improvement, likely suffering from cross-platform inconsistencies or low prominence. Document this score meticulously, noting the date, the prompt set, and the platform distribution.
Step 4: Analyze Competitor Baselines Your visibility score exists in a competitive vacuum until compared against market alternatives. Run the exact same prompt clusters and calculate the Visibility Score for your top three competitors. If your score is 45 but the market leader scores 82, the benchmark immediately contextualizes the severity of your visibility deficit.
Step 5: Set Your Measurement Cadence Benchmarks are only valuable if they are tracked over time. Generative models update frequently, and visibility can shift overnight based on new data ingestion or algorithmic tweaks. Establish a weekly or bi-weekly tracking cadence to monitor trend lines, identify sudden drops, and correlate visibility changes with your citation optimization efforts.
Selecting the Right Prompts
The quality of your benchmark depends entirely on the quality of your prompt set. Avoid overly broad or strictly navigational queries. Focus on commercial and comparative intents where the AI acts as an advisor rather than a mere dictionary. Include edge cases, specific industry verticals, and feature-level comparisons to map the full spectrum of how users might discover your brand through generative engines.
Analyzing Citation Intelligence and Source Influence
Visibility is the outcome; citations are the input. Once you have established your brand visibility benchmark, the next analytical step is understanding why you are appearing in generative answers. This requires deep analysis of Citation Intelligence.
Generative models, particularly search-augmented models like Perplexity and Google AI Overviews, cite their sources when constructing answers. If your brand is highly visible, it is because the models are consistently retrieving information from specific, authoritative domains that mention you favorably. Conversely, if your visibility is low, it is often because your competitors dominate the specific sources that the AI trusts most for your category.
When benchmarking, document the most frequently cited domains for your prompt clusters. Are the models pulling from Reddit threads? Technical review sites like G2 or Capterra? Major industry publications? Or perhaps directly from vendor documentation?
By mapping the citation graph, you can identify the "kingmaker" domains in your industry. If Perplexity consistently cites a specific technology blog when answering queries about your product category, and your brand is absent from that blog, your path to improving your benchmark is clear: you must secure coverage on that specific domain.
Generic SEO benchmarks ignore AI-specific signals like citation freshness and source alignment. Traditional link building focuses on acquiring links from any high-Domain Authority site to boost your own website's ranking. Citation optimization, however, requires a surgical approach. You must target the exact URLs and domains that generative models are actively retrieving to construct answers in your space. Tracking citation share alongside your Visibility Score provides a complete picture of both your performance and the underlying levers controlling it.
The Role of Organic Brand Detection
A mature benchmarking strategy must account for the dynamic, often unpredictable nature of generative AI outputs. Unlike traditional SERPs where competitor targeting is generally static, AI models frequently introduce new market entrants, substitute products, or tangential solutions into their answers.
This is where Organic Brand Detection becomes essential. When you run your benchmark prompt clusters, you should not only track your brand and your known competitors but also algorithmically detect any new entities the AI introduces.
For example, you might ask Claude to "Compare the best project management tools for creative agencies." You expect it to mention Asana, Monday, and your own tool. But what if it consistently recommends a newly launched, niche agency management platform you had never considered a direct threat?
Organic Brand Detection auto-discovers competing brands appearing in answers, alerting you to shifts in the competitive landscape before they register in traditional market share reports. By benchmarking the frequency of these unexpected brand mentions, you can identify emerging threats and understand how generative models are categorizing your industry.
If an unknown competitor suddenly spikes in visibility across multiple platforms, it indicates a successful PR push, a viral moment, or a significant update to their documentation that has caught the attention of AI retrieval mechanisms. Monitoring these organic appearances ensures your benchmarks reflect the reality of the AI's knowledge base, rather than a rigid, outdated view of your competitive set.
Overcoming Common Benchmarking Challenges
Organizations implementing AI brand visibility benchmarking often encounter specific operational challenges. Anticipating these hurdles ensures the integrity and longevity of your measurement framework.
The Problem of Personalization and Hallucination Generative models are inherently non-deterministic. The same prompt asked twice might yield slightly different phrasing or a reordered list of recommendations. Furthermore, models can hallucinate, inventing features or misattributing capabilities. To overcome this, benchmarking must rely on statistical aggregation rather than single-shot queries. By running prompts multiple times and averaging the results, you smooth out anomalous responses and capture the model's consistent baseline behavior. Tools like PromptEden handle this aggregation automatically, providing a stable Visibility Score despite underlying model variance.
Tracking API vs. Web Interface Behavior It is vital to recognize that an AI model's behavior via its API can differ significantly from its behavior in its consumer-facing web interface. Web interfaces often include proprietary retrieval-augmented generation (RAG) overlays, specific system prompts, and real-time browsing capabilities that may be absent or configured differently in raw API calls. When benchmarking, ensure your methodology accounts for the actual end-user experience. If your buyers use the ChatGPT web interface, your benchmark data must reflect web-retrieval outcomes, not just the raw capabilities of the underlying GPT-4 model.
Managing Scale and Cost Manual prompt auditing—typing queries into multiple platforms and recording the results in a spreadsheet—is viable for an initial pilot but impossible to scale. As your prompt clusters grow and you require daily or weekly tracking across nine different platforms, manual benchmarking becomes prohibitively expensive in terms of human capital. Enterprise AEO requires automated monitoring solutions. Leveraging a dedicated platform to execute, score, and trend your prompt clusters ensures consistent data collection without overburdening your marketing operations team.
Next Steps for Your Measurement Strategy
Benchmarking is not a one-time project; it is the continuous pulse of your AEO program. Once you have established your initial baseline, the focus shifts to optimization and trend analysis.
First, socialize your Visibility Score across the organization. Educate leadership on the difference between traditional SEO traffic and AI recommendation share. Demonstrate the cross-platform visibility gaps and highlight the specific citation sources that are influencing the models.
Second, launch targeted citation optimization sprints based on your benchmarking data. If your benchmark reveals low prominence on Gemini, investigate the specific sources Gemini prefers for your industry and prioritize coverage on those domains.
Third, monitor specific prompts over time and catch shifts early. Track day-over-day and week-over-week changes in visibility. When a major model update occurs—such as the release of a new Claude architecture or a fundamental change to Google AI Overviews—immediately review your benchmarks to understand the impact on your brand.
By treating AI brand visibility as a core operational metric, you transition from reacting to the generative AI landscape to actively managing your presence within it. Consistent benchmarking provides the clarity needed to dominate the next era of search and discovery.